

大写数字壹贰叁肆到拾怎么写?大写数字一到十金额怎么写?
大写数字壹贰叁肆到拾怎么写?大写数字一到十金额怎么写?写收据、开发票的时候,我们一般是需要用大写的数字一到十来写金额的。但是对于许多80末、90后的朋友来说,如(244)人阅读时间:2020-07-16 11:02:48
一寸等于多少厘米?一寸照片尺寸是多大?
一寸等于多少厘米?一寸照片尺寸是多大?寸是旧时单位,现在很多人没有寸这个概念,更不清楚一寸等于多少厘米。虽然不知道这个,但一寸照片你总拍过吧,可一寸照片尺寸是多少(159)人阅读时间:2020-07-16 11:02:48
非常的近义词是什么?非常的反义词是什么?用非常造句
非常的近义词是什么?非常的反义词是什么?非常是一个常见常用的汉语词语,同学们应该并不陌生,在课文中经常会遇到。那你知道非常的近义词和非常的反义词都是什么吗?怎(610)人阅读时间:2020-07-16 11:02:48
139邮箱登录登录入口 手机号就是邮箱号
139邮箱登陆登录入口是一款由中国移动官方所推出的专业级邮件处理软件,139邮箱登陆的功能十分强大,支持手机电脑端互通、多账号登录以及还能够为用户提供qq、sina、(423)人阅读时间:2020-07-16 11:02:482022年成都做面部拉皮最好的医生预约排名
 成都做面部拉皮最好的医生是谁?成都做拉皮手术最好的医生:李治浩、侯典举、董玉林、蒲兴旺、何一波等,医生反馈口碑不错,建议实地面诊和对比,选择..2020-07-16
成都做面部拉皮最好的医生是谁?成都做拉皮手术最好的医生:李治浩、侯典举、董玉林、蒲兴旺、何一波等,医生反馈口碑不错,建议实地面诊和对比,选择..2020-07-162022年上海做隆鼻修复技术好的医生有哪些?
 上海做鼻修复好的医生是谁?上海做鼻修复好的医生:戴传昌、王会勇、李健、王艳、钱玉鑫、范荣杰、许炎龙、赵延峰等,技术和审美反馈不错,建议实地..2020-07-16
上海做鼻修复好的医生是谁?上海做鼻修复好的医生:戴传昌、王会勇、李健、王艳、钱玉鑫、范荣杰、许炎龙、赵延峰等,技术和审美反馈不错,建议实地..2020-07-16姚乃君面部提升技术速提美提升价格?
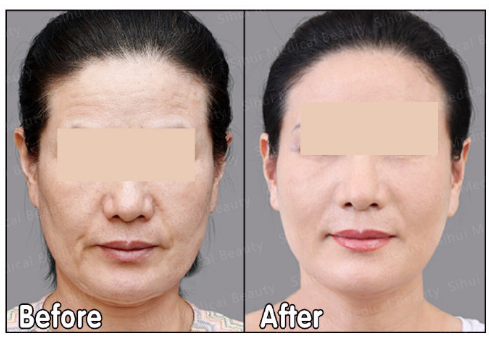 姚乃君面部提升技术怎么样,速提美提升贵不贵?姚乃君的面部提升技术属于微创方式,效果维持时间在2年左右,术后即刻见效果,速提美提升价格:3-4万,具体..2020-07-16
姚乃君面部提升技术怎么样,速提美提升贵不贵?姚乃君的面部提升技术属于微创方式,效果维持时间在2年左右,术后即刻见效果,速提美提升价格:3-4万,具体..2020-07-162022年西京医院做鼻子做得好的大夫是谁?
 西京医院做鼻子做得好的大夫是谁?西京医院隆鼻最好的医生:金长鑫、张曦、宋保强、彭湃等,建议实地面诊和对比,选择医生需谨慎,预约或咨询添加微信..2020-07-16
西京医院做鼻子做得好的大夫是谁?西京医院隆鼻最好的医生:金长鑫、张曦、宋保强、彭湃等,建议实地面诊和对比,选择医生需谨慎,预约或咨询添加微信..2020-07-16






